Ich hatte vor kurzem einen Supportfall, bei dem mich ein Kunde um Rat gefragt hat, weil irgendwie das Failover Cluster nicht alles korrekt anzeigt. Ich habe mich denn dazu geschaltet und mir das Cluster angeschaut, und dabei eine äußerst interessante Entdeckung gemacht, die mir bisher so auch noch nicht untergekommen ist. Aber von vorne…
Wie es sein müsste…
Normalerweise gibt es in einem Failover Cluster ein paar Standard-Ressourcen, die immer vorhanden sind. Dies ist ein Quorum (entweder als Datenträger, als Dateifreigabe oder als Azure Cloud Witness, je nach Cluster), der Failover Cluster Name sowie die IP-Adresse, unter der das Failover Cluster erreichbar ist.
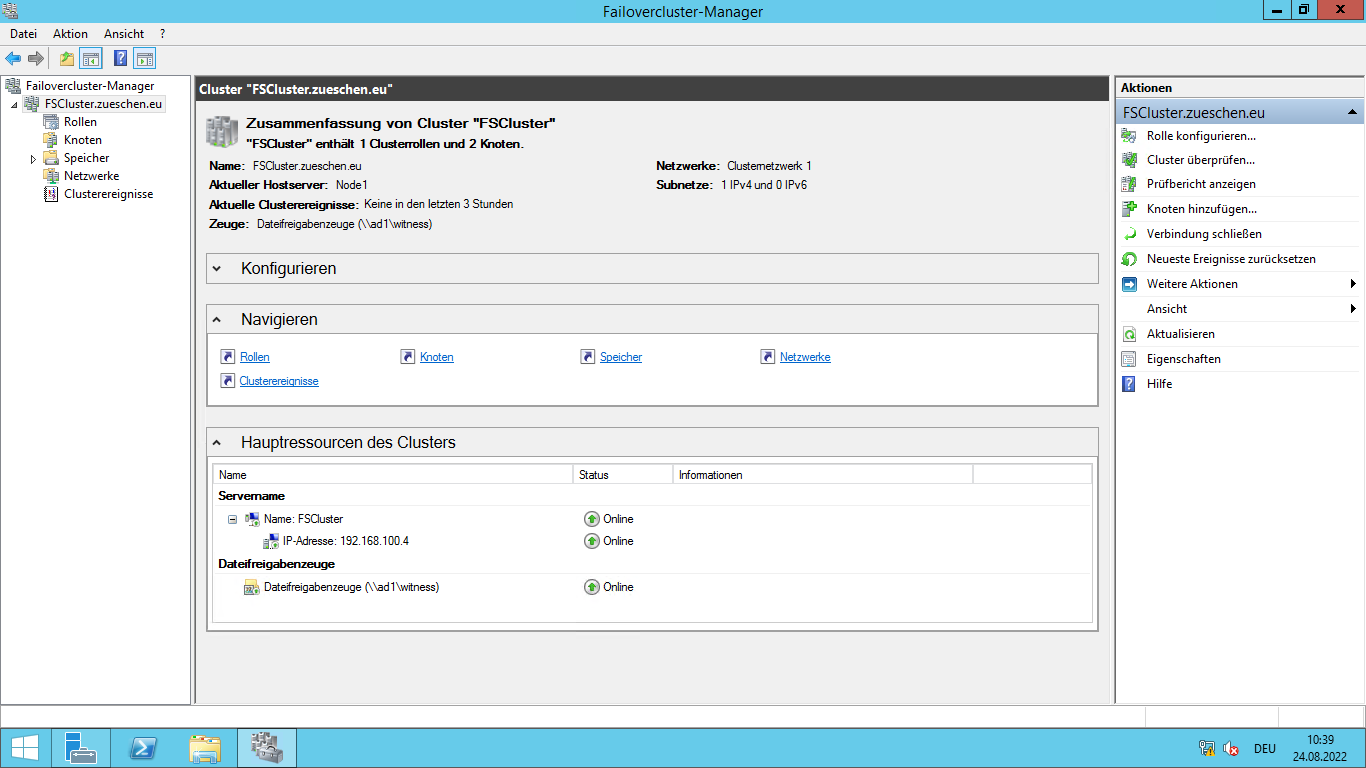
Man kann diese Ressourcen auf der Übersichtsseite des Failover Cluster sehen (unterer Bereich), alternativ können die Informationen natürlich auch per PowerShell abgerufen werden.
Get-ClusterResource
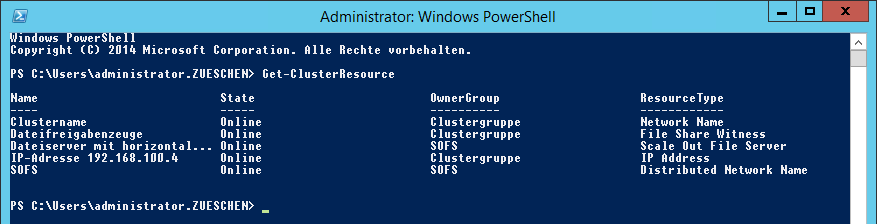
Hauptressourcen des Clusters zeigt keinen Namen und keine IP mehr an
In meinem Supportfall war es so, dass auf der Hauptseite nur noch das Witness angezeigt wurde, die anderen Ressourcen waren nicht mehr vorhanden. Die Administration des Clusters hat aber trotzdem funktioniert, und man konnte auch wie gewohnt eine Verbindung aufbauen. Name und IP-Adressen waren wohl noch da. Nach einem Aufruf des PowerShell-Befehls zeigte sich dann, dass die Ressourcen an einer falschen Stelle sitzen. Name und IP-Adresse des Clusters waren der Scale-Out File Server Rolle zugeordnet. Das sieht dann in der grafischen Oberfläche wie folgt aus.
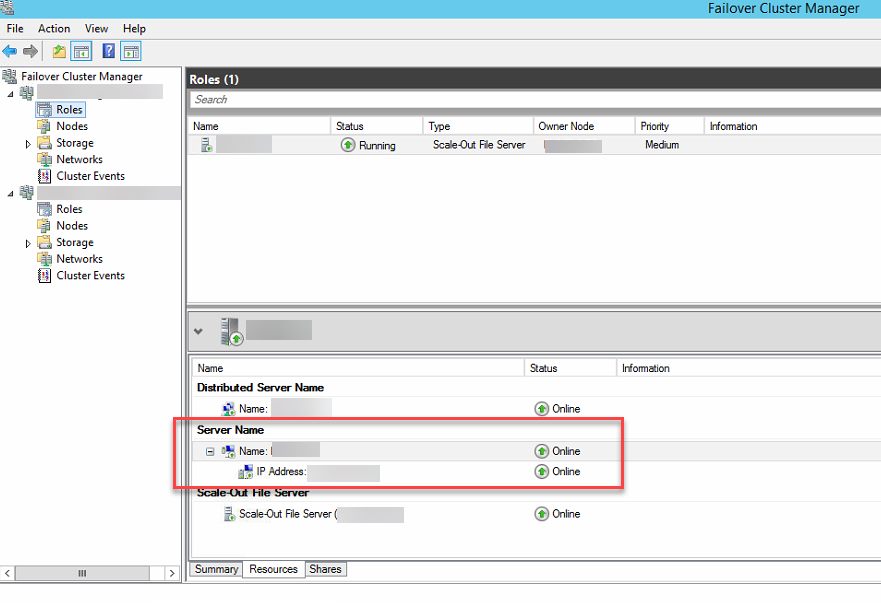
Die Lösung
Um die Ressourcen wieder an die korrekte Stelle zu bringen, müssen Sie in die korrekte Besitzergruppe bzw. OwnerGroup verschoben werden. Die Verschiebung hat den Vorteil, dass keine Ressourcen gelöscht und per Hand wieder erstellt werden müssen. Die Befehle dazu sind wie folgt:
Get-ClusterResource
Dieser Befehl zeigt an, welche Ressourcen aktuell im Cluster vorhanden sind, und zu welcher OwnerGroup sie gehören. Hier gibt es einen Unterschied bei einem deutschen System zu einem englischen. Im deutschen System heißt die Gruppe Clustergruppe, auf einem englischen System ist es Cluster Group. Der Name der übrigens Ressourcen ist teilweise auch anders, dies muss jeweils pro Cluster überprüft und kopiert werden. Uns geht es um die beiden Ressourcen Clustername (deutsch) bzw. Cluster Name (englisch) sowie IP-Adresse 192.168.x.x (deutsch) bzw. Cluster IP Address (englisch).
Get-ClusterResource „Cluster IP Address“ | Move-ClusterResource -Group „Cluster Group“
Dieser Befehl verschiebt auf einem englischen System die Gruppenzugehörigkeit in die korrekte Gruppe.
Get-ClusterResource „Cluster Name“ | Move-ClusterResource -Group „Cluster Group“
Dieser zweite Befehl bewegt das Objekt Cluster Name auf einem englischen System in die korrekte Gruppe.
Nachdem die Befehle abgesetzt wurden, kann der Besitz nochmal überprüft werden mit einem
Get-ClusterResource
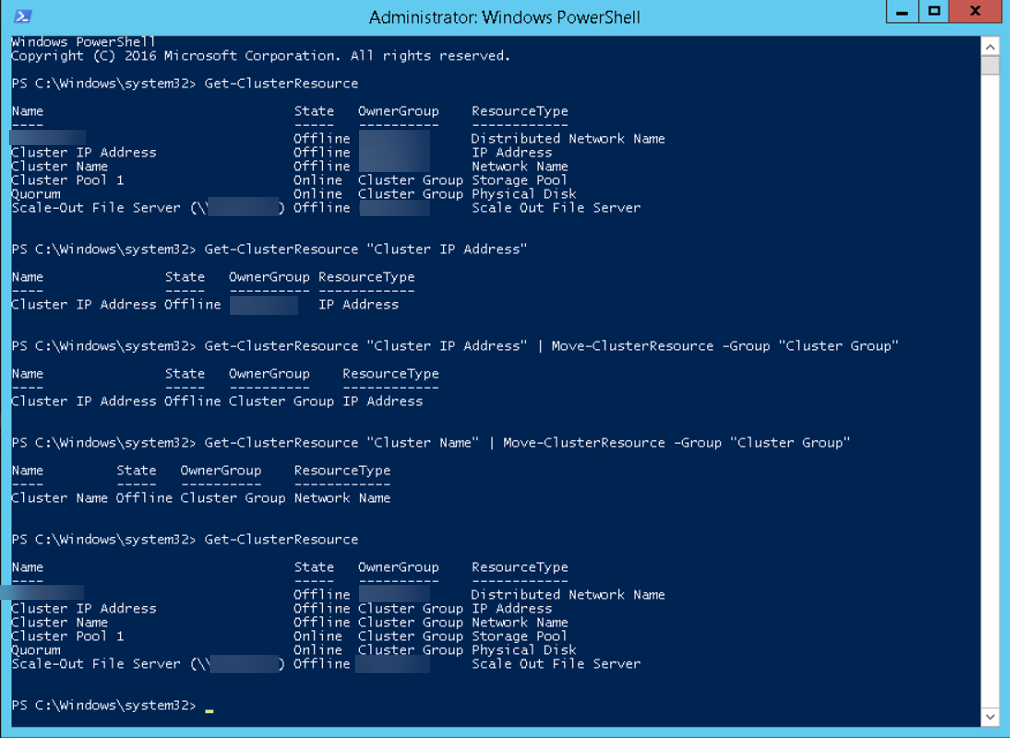
Wir können im (zensierten, da Kundensystem) Screenshot erkennen, dass die beiden Ressourcen im oberen Bereich zur OwnerGroup der SOFS-Rolle gehören. Nachdem ich die beiden Ressourcen verschoben habe, kann man in der unteren Abfrage sehen, dass die OwnerGroup danach die Cluster Group ist.
Fazit
Mit dieser Änderung werden die Ressourcen nun wieder ordnungsgemäß angezeigt und zeigen sich im Failover Cluster Manager nun auch wieder auf der Übersichtsseite des Clusters. Durch die Verschiebung der beiden Ressourcen in eine andere Gruppe müssen wir nichts löschen und neu anlegen, dies vermindert das Risiko von einem ungeplanten Ausfall oder von Verbindungsproblemen zum Failover Cluster. Ich selbst habe die Rollen (wie man in den Screenshots sieht) während des Umzugs Offline genommen, das war mir sicherer, ich vermute die Änderung kann aber auch online gemacht werden. Da wir aber sowieso ein Wartungsfenster hatten, und wir die Hyper-V VMs sowie die SOFS-Rolle offline nehmen konnten, haben wir das auch gemacht.

