Im zweiten Teil dieser kleinen Reihe schauen wir uns an, wie Minemeld konfiguriert werden muss, damit man seine eigenen Filterlisten nach Bedarf erstellen und nutzen kann. Wer den ersten Teil der Installation verpasst hat:
Dynamische Palo Alto Firewall-Regeln basierend auf Minemeld – Teil 1
Wie funktioniert Minemeld?
Für die Erstellung von einer eigenen Filterliste sind drei Komponenten notwendig und verantwortlich:
- Ein Miner
- Ein Processor und
- Ein Output Node
In dem Artikel von Palo Alto ( live.paloaltonetworks.com ) ist ein sehr gutes Schaubild dazu vorhanden:
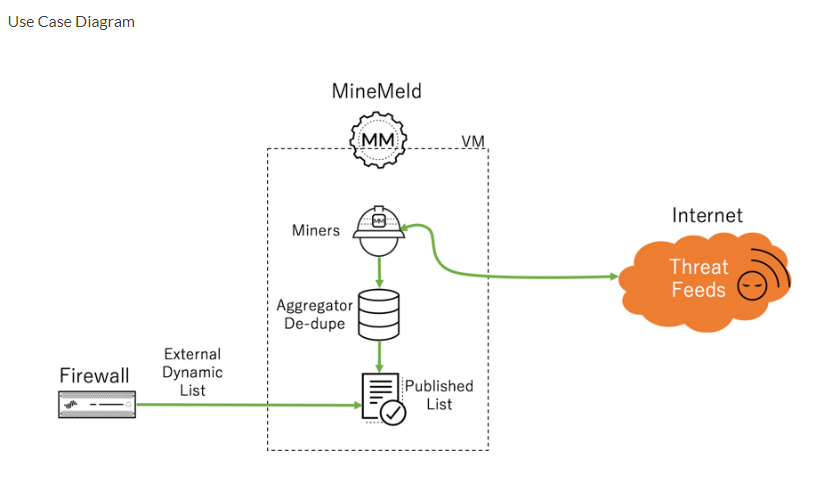
Man erkennt hier sehr gut, dass der Miner dafür verantwortlich ist, die Daten aus dem Internet zu ziehen und lokal abzulegen. Im Prinzip handelt es sich um einen Worker-Prozess, wie man ihn auch aus anderer Software kennt. Es kann auch mehrere Miners gleichzeitig geben, die unterschiedliche Arten von Listen zusammentragen (z.B. ein Worker für die Office365-Adressen und ein weiterer für eine Liste mit IP-Adressen, die Locky-Malware verteilen).
Die Daten, die vom Miner besorgt und heruntergeladen werden, werden nun lokal aufgearbeitet (es werden z.B. doppelte Einträge entfernt) und danach als Datei veröffentlicht. Die Veröffentlichung passiert auf dem Server selbst, die Daten stehen über den nginx zur Verfügung und können per HTTP/HTTPS von der Palo Alto Firewall heruntergeladen und genutzt werden.
Anlegen einer benutzerdefinierten Liste
Ich möchte in meinem Fall eine Liste generieren, die alle von Microsoft genutzten IP-Adressen für Office 365 enthält. Wir wechseln zu Config im oberen Menü, danach sehen wir die nach der Installation standardmäßig enthaltenen Einträge.
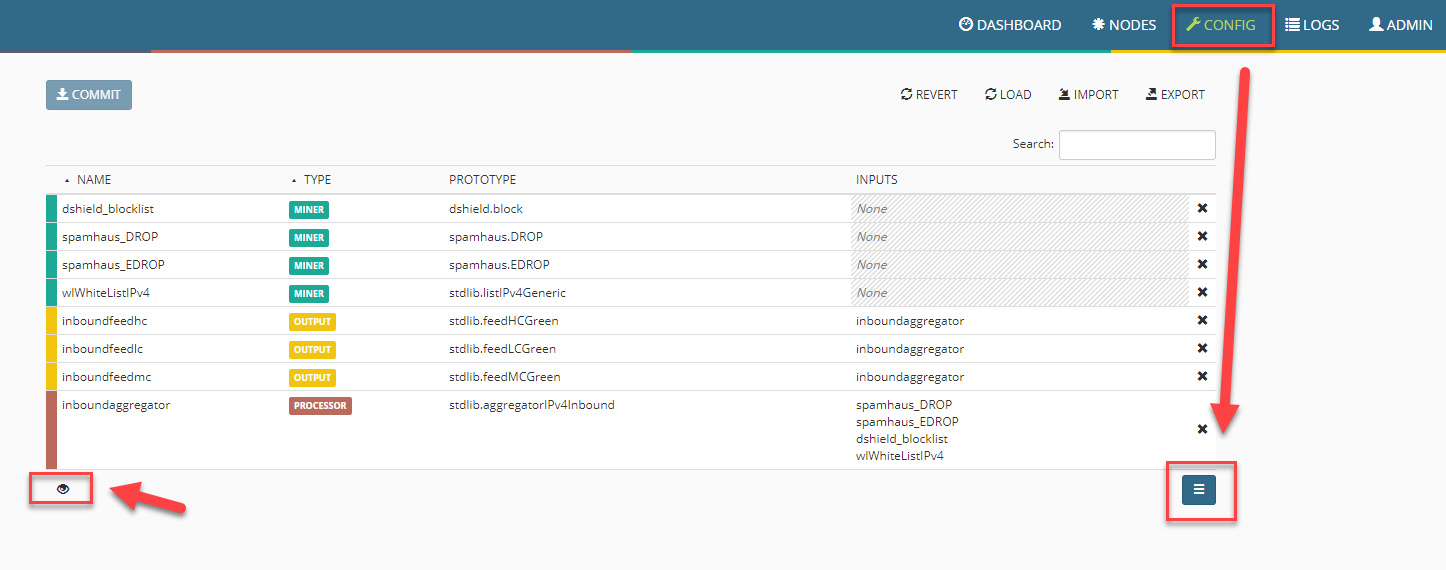
Tipp: unten links das keine Auge schaltet um in das erweiterte Menü, damit lassen sich noch ein paar mehr Optionen aktivieren.
Ein Hinweis zum allgemeinen Verständnis:
Prototypen sind Vorlagen, die erst einmal nur da sind. Basierend auf einer Vorlage kann man dann einen Node erzeugen, erst durch diese Aktion wird die Aufgabe aktiv ausgeführt (z.B. der Abruf von IP-Adressen oder die Ausgabe als TXT-Datei).
Prototyp
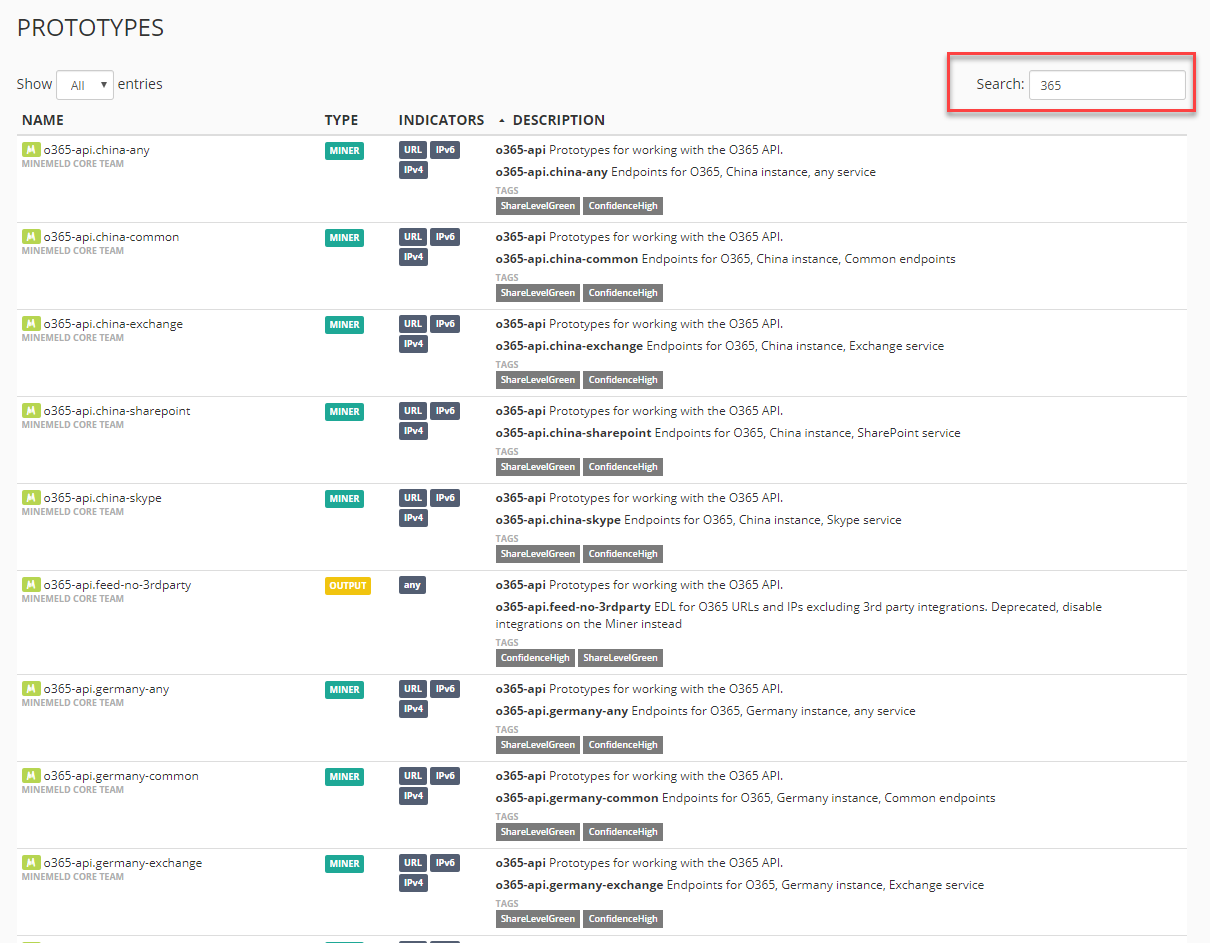
Klickt man auf den Button mit den drei Strichen, erscheint eine Liste aller verfügbaren Prototypes. Zum aktuellen Zeitpunkt sind dies 255 Stück. Filtert man nach dem Wort 365, reduziert sich die Liste auf alle Einträge, die etwas mit Office 365 zu tun haben.
Tipp: Fügt man in die manuell erzeugten Elemente z.B. den Firmennamen oder einen speziellen Tag ein, sind die Elemente später deutlich leichter zu finden!
Hier können wir nun die für uns beste Liste heraussuchen. Da ich gerne alle Adressen hätte, nutze ich die Liste o365-api.worldwide-any.
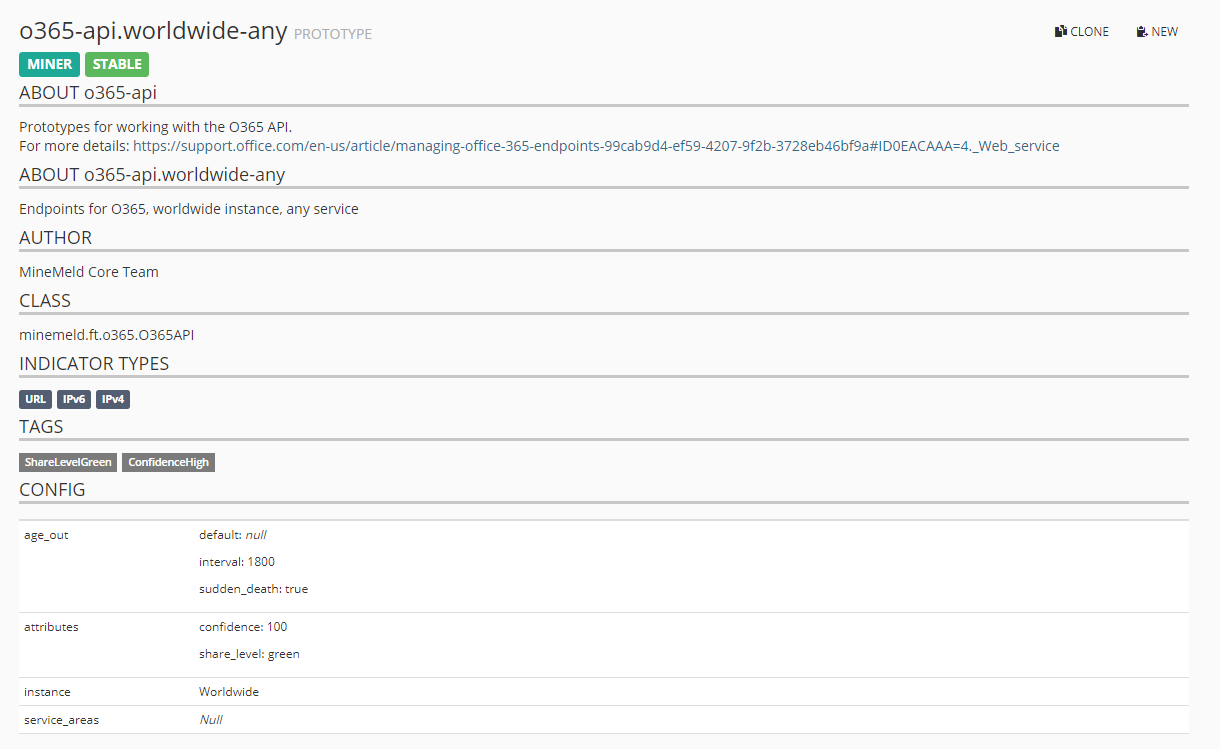
Nach einem Klick auf NEW oben rechts wird eine Kopie des Prototypen erstellt, bei Bedarf können hier noch Einstellungen und Parameter angepasst werden:
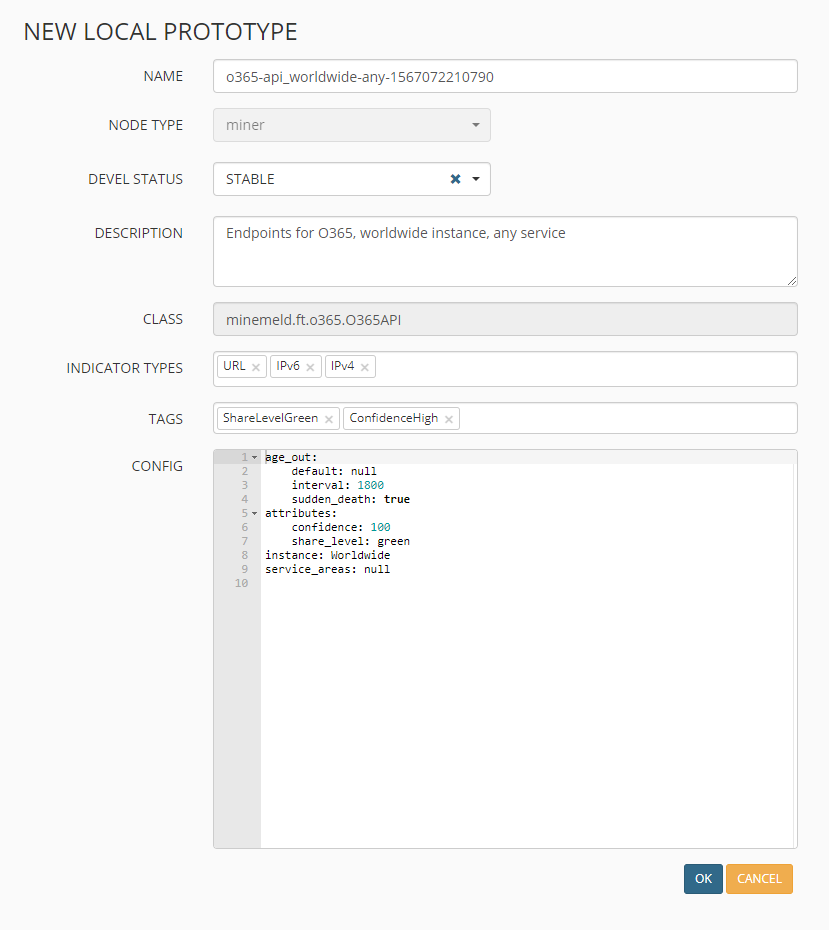
Miner
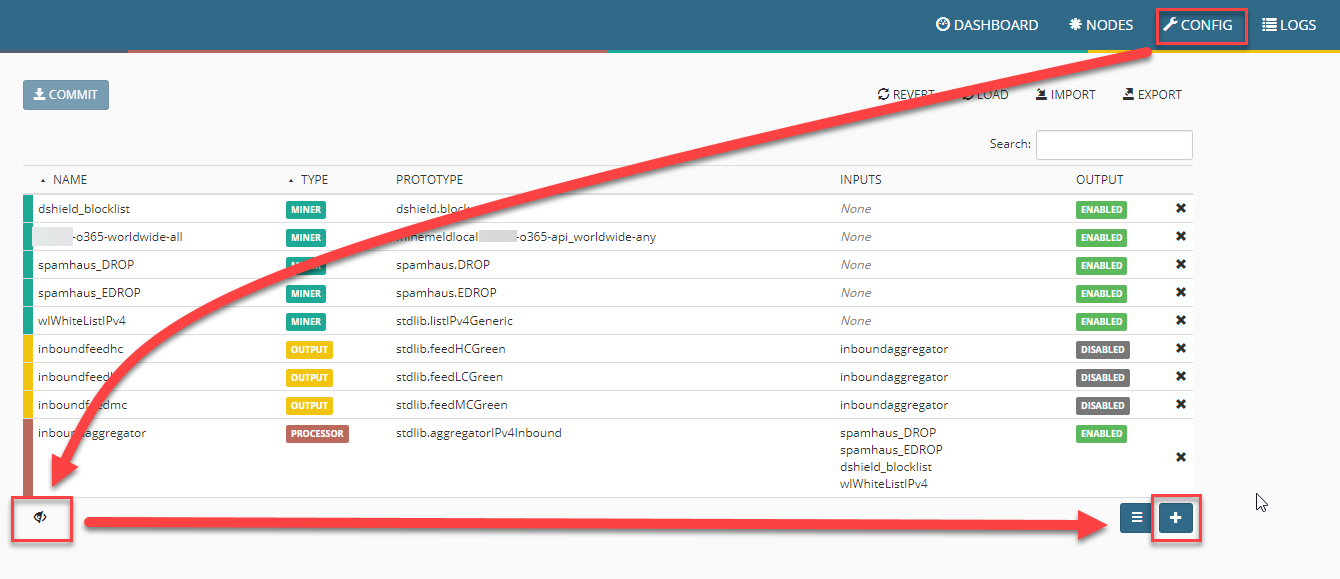
Nachdem nun der Prototyp erstellt ist, kann der dazu benötigte Miner erstellt werden. Hierzu klicken wir im Bereich Config auf den Expertenmodus und wählen unten rechts das +.
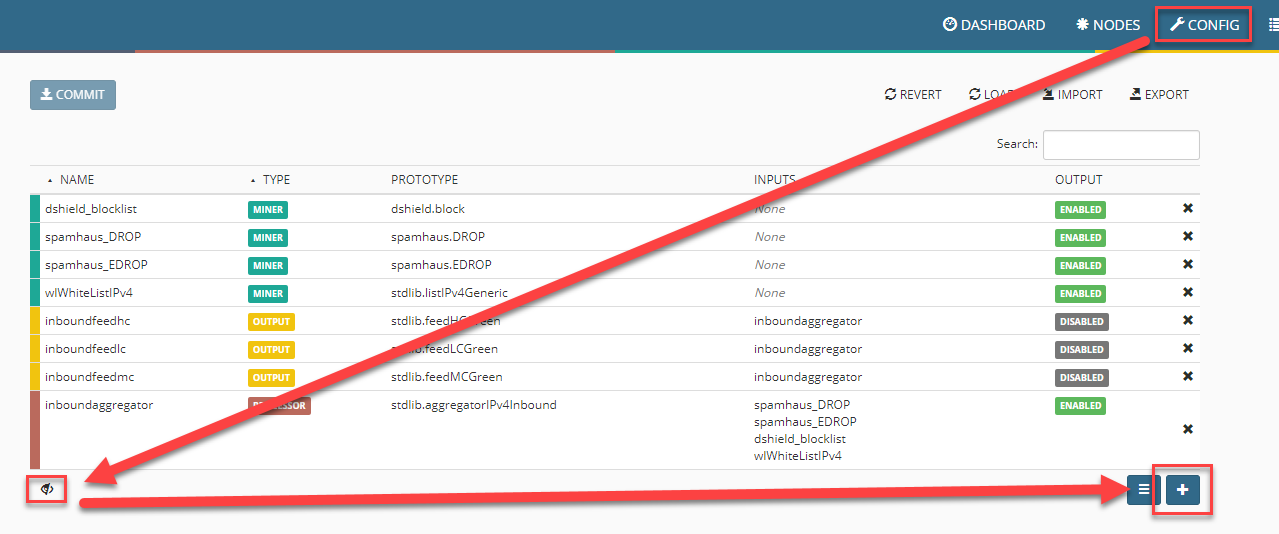
Hier können wir dem neuen Node einen aussagekräftigen Namen geben und den gerade erzeugten Prototyp zuweisen.
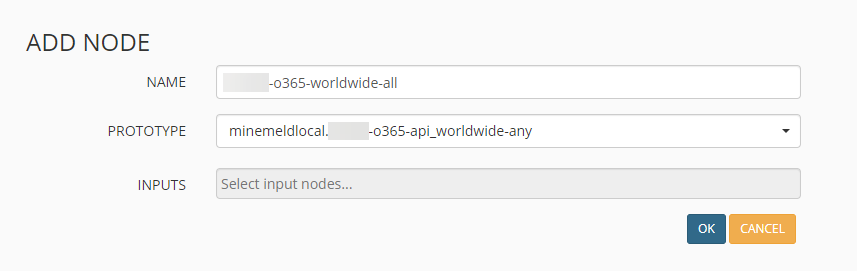
Processor
Um die Daten verarbeiten zu können, wird nun ein Processor hinzugefügt. Dies geschieht ebenfalls über Config und den kleinen Button mit den drei Strichen unten rechts.
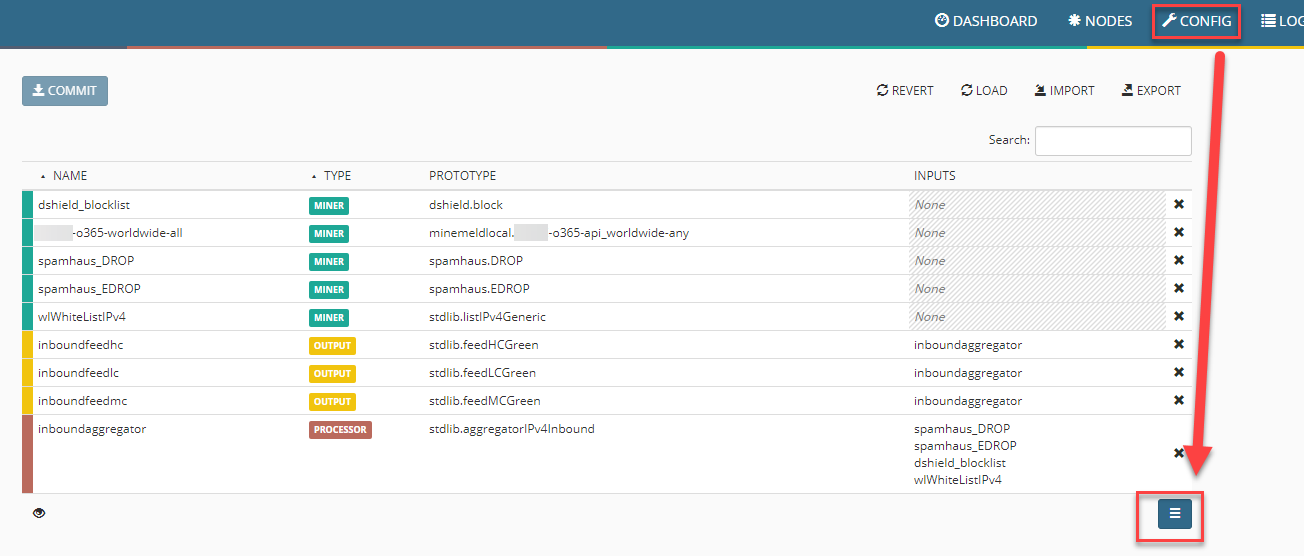
Nun können wir die Liste wieder filtern, der benötigte Processor hat den Namen stdlib.aggregator, gefolgt von dem Typ der Daten, die verarbeitet werden sollen (IPs, Domains, URLs, …). Ich nutze in diesem Beispiel den Aggregator stdlib.aggregatorIPv4Generic.
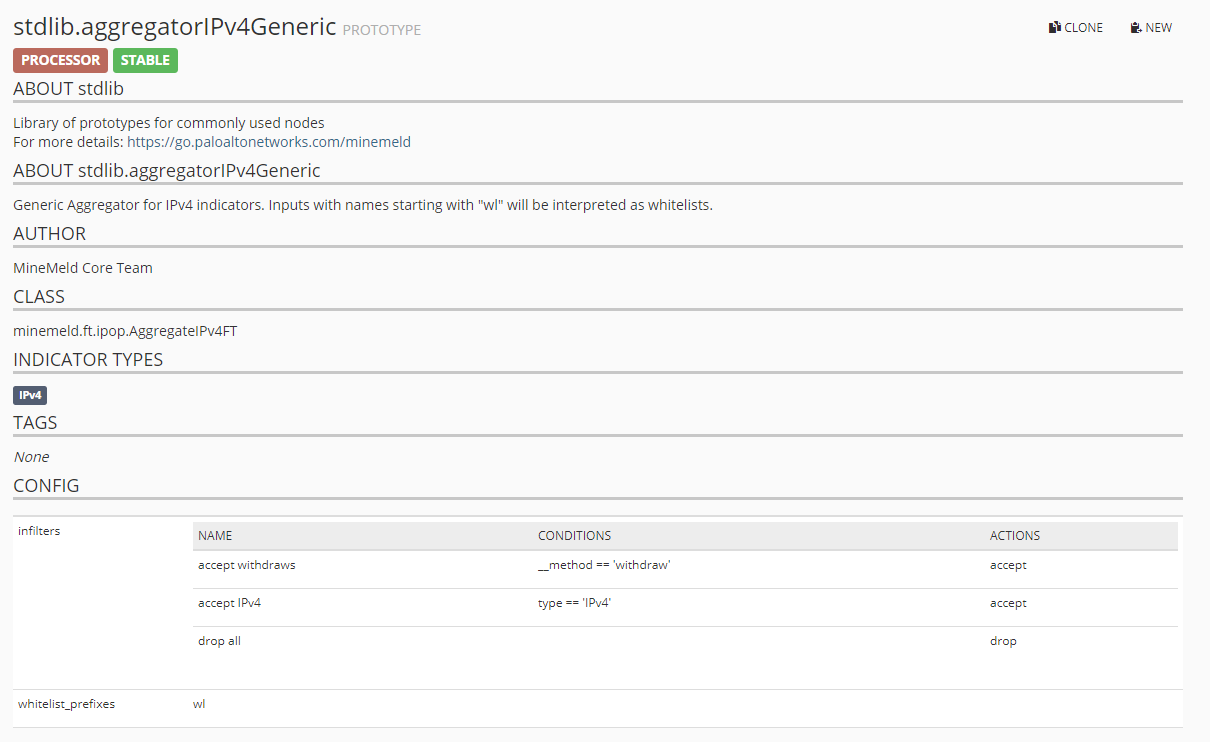
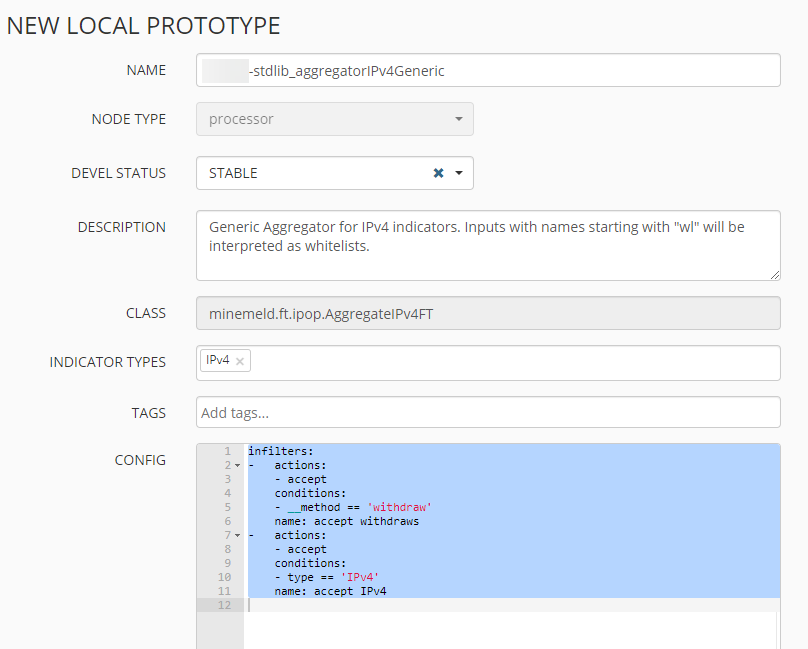
Mit der Option NEW legen wie eine Kopie an, hier müssen wir nun eine Anpassung an der Konfig vornehmen. Die Standard-Konfig wird ersetzt durch
infilters:
- actions:
- accept
conditions:
- __method == 'withdraw'
name: accept withdraws
- actions:
- accept
conditions:
- type == 'IPv4'
name: accept IPv4
Zusammenführung von Node und Processor
Nun können wir den vorhin erstellten Node mit dem gerade erstellten Processor zusammenfügen. Dies geht unter Config mit der Option ADD.
Hier wählen wir an den drei Stellen unsere soeben erstellten Elemente aus, hier kommt uns (wie angesprochen) der einzigartige Name / Tag zu Gute.
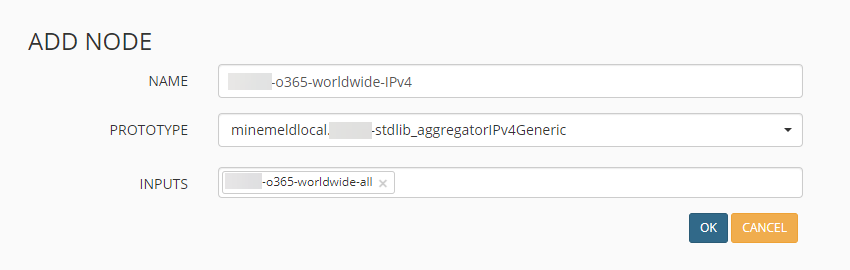
Der Output
Als letzten Schritt müssen wir nun noch definieren, wie und wo die Ausgabe der IPv4-Adressen passiert. Hierzu erzeugen wir einen neuen Prototype vom Typ stdlib.feedGreenWithValue.
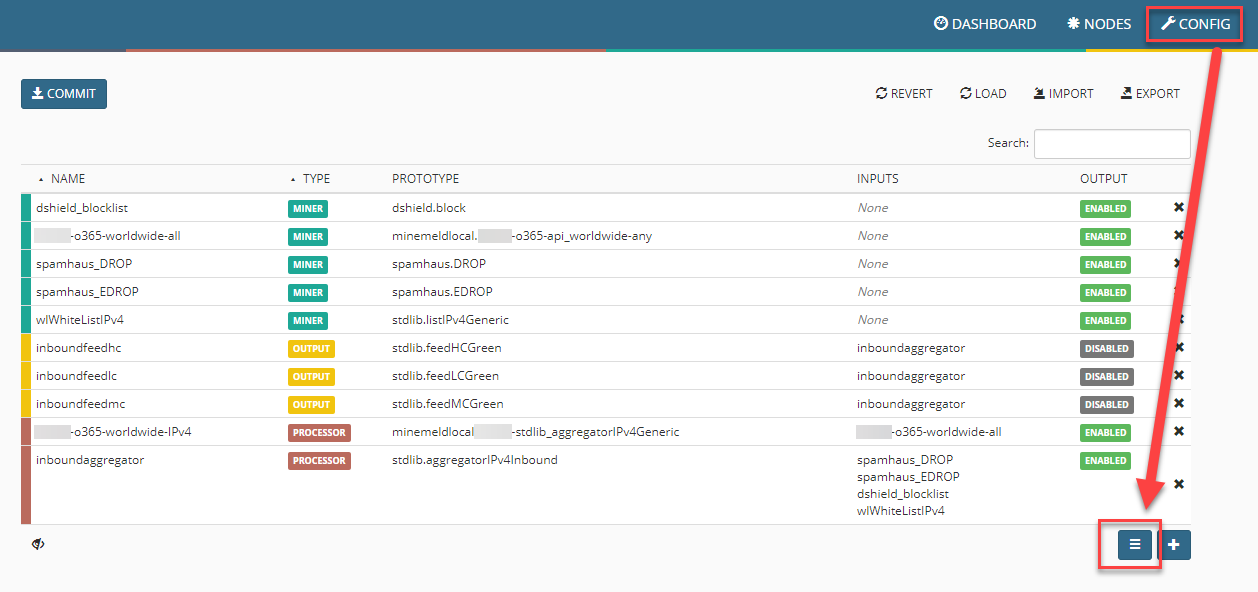
Suchen wir nach feedGreenWithValue, erscheint unser gewünschter OUTPUT-Processor.
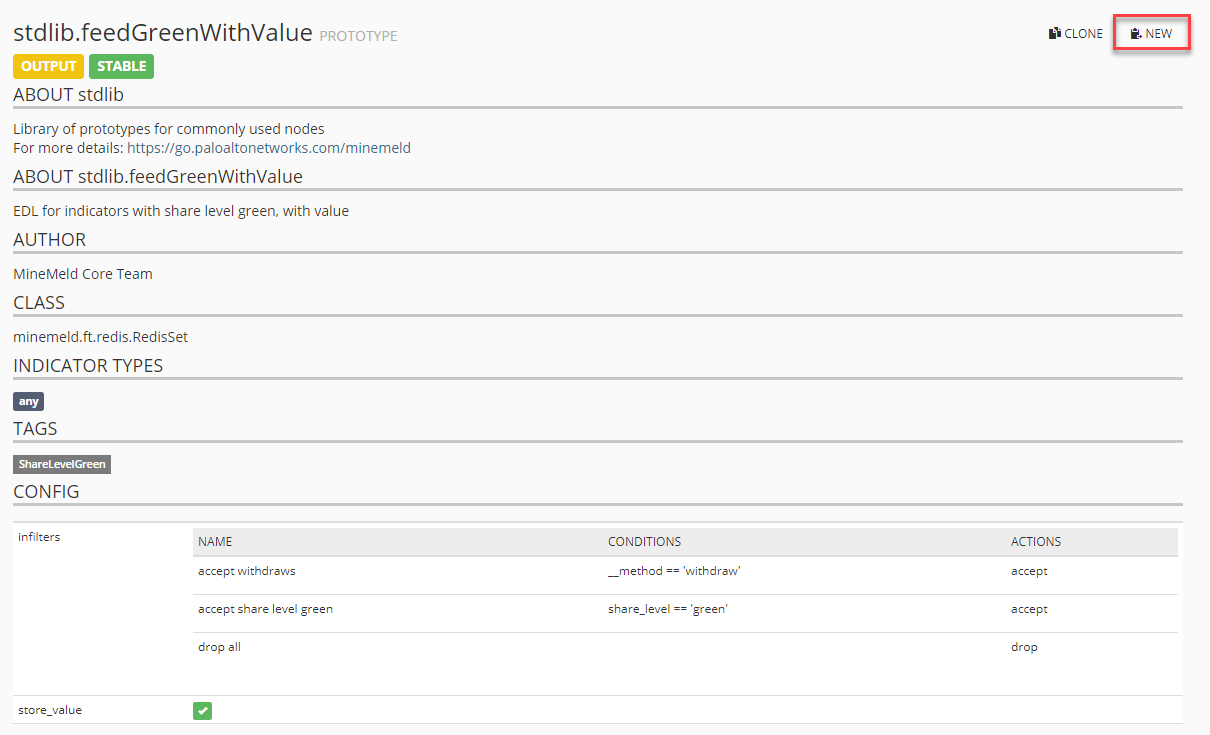
Mit einem Klick auf NEW legen wir eine manuelle Kopie an, auch hier müssen wir wieder die Konfiguration anpassen.
infilters:
- actions:
- accept
conditions:
- __method == 'withdraw'
name: accept withdraws
- actions:
- accept
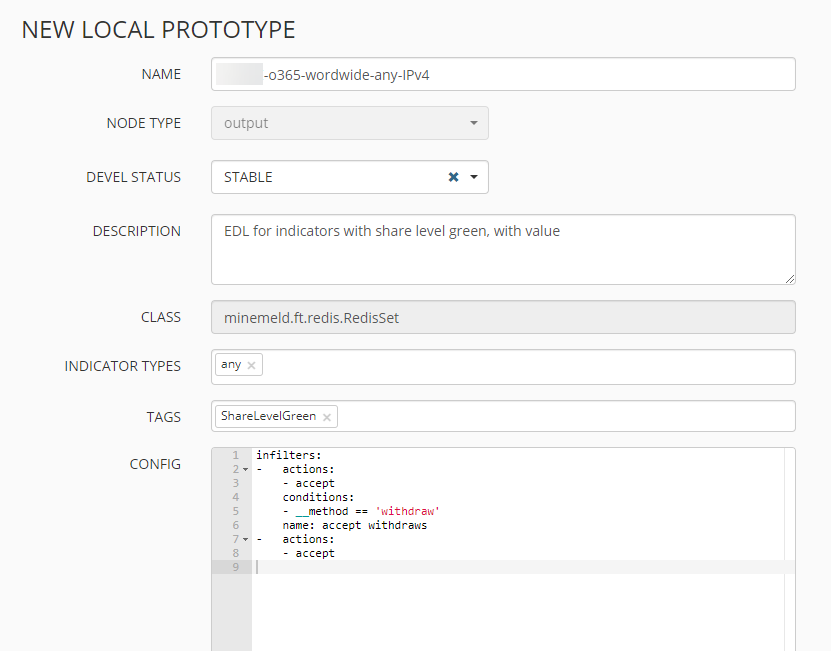
Nachdem wir nun den Prototyp angelegt haben, können wir auch hierzu einen aktiven Node anlegen. Dies geschieht wieder über CONFIG => ADD NODE.
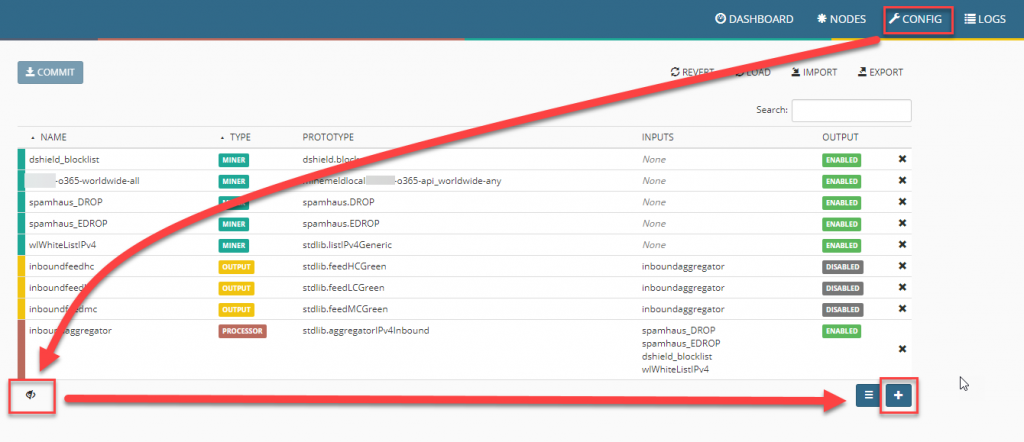
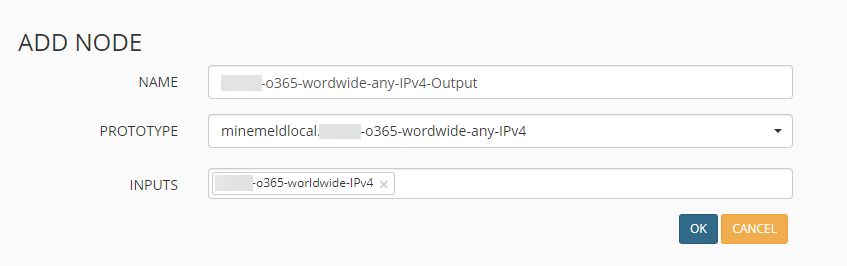
Nach einem Klick auf OK sind alle benötigten Schritte gemacht, die gesamte Konfiguration muss nun noch mit einem Klick auf COMMIT gespeichert werden.
Prüfung auf Funktionalität
Um nun zu prüfen, ob alles korrekt konfiguriert ist, kann man einen Blick in die Nodes werfen:
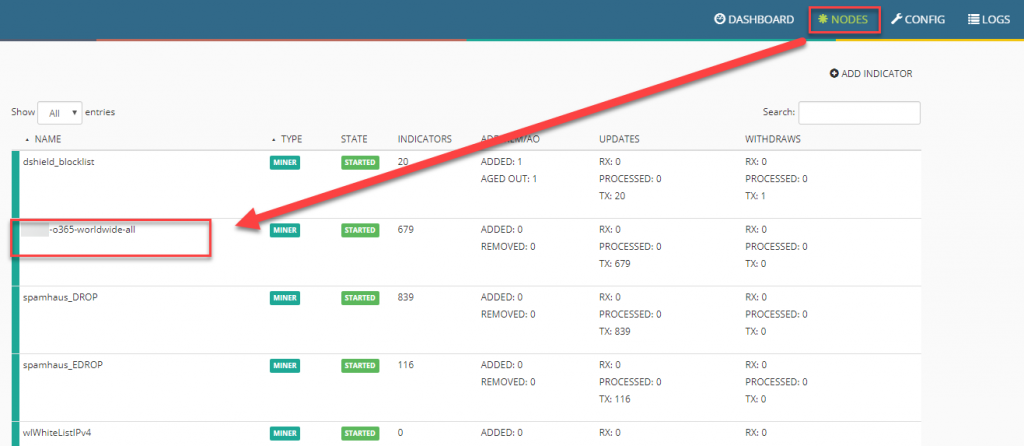
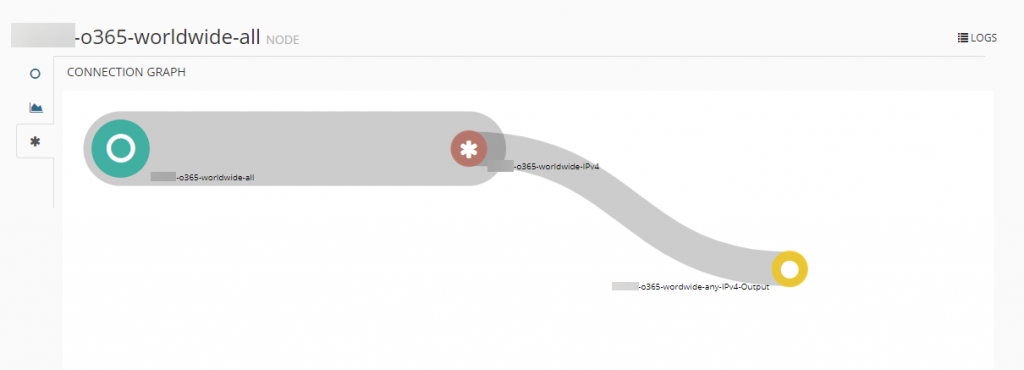
Wir sehen hier die Verbindung zwischen den drei Nodes, die wir erstellt haben
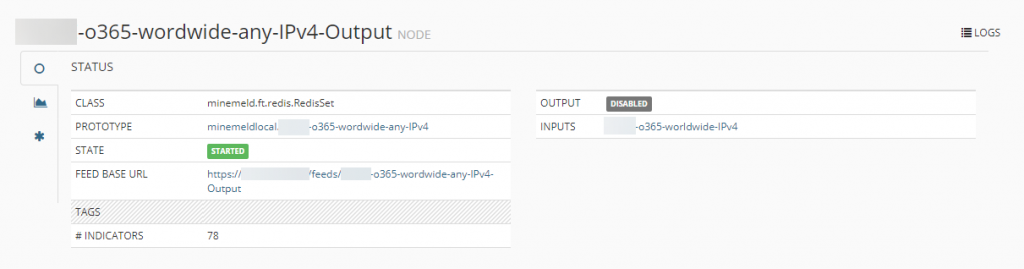
Ein Klick auf den gelben Output-Punkt führt uns in die Einstellungen vom Output-Node, hier sehen wir dann auch die URL, unter der wir die Filterliste aufrufen und einsehen können (FEED BASE URL):
Ein Aufruf im Browser sieht dann wie folgt aus:
Im nächsten Teil schauen wir uns dann an, wie wir diese Listen in der Palo Alto Firewall einziehen und für ein Regelwerk nutzen können.

